
ObsPack Specification
V 2.0
Jun 9, 2022
Introduction
ObsPack is a format for delivering atmospheric trace gas measurements for use in models and other analyses (Masarie et al. 2014). It was developed in conjunction with the GLOBALVIEW plus product, as the features of that product required an extensible and flexible delivery format. This document is intended to update the specifications in Masarie et al. to reflect developments that have occurred since that article was written.Definition of a dataset
The concept of a “dataset” is fundamental to the structure of an ObsPack product. A dataset is a time series of measurements of the same species at a specific site, from the same laboratory using the same location, sampling scheme, selection criteria, and measurement technique.A dataset is named with underscore-delimited fields representing chemical species, site code, platform, laboratory, and selection scheme. The dataset name is used as part of the unique identifier for each measurement. Continuity of these names is expected across ObsPack products, and care should be taken to not change dataset names unless it is absolutely necessary.
A canonical example of a dataset is the time series of quasi-continuous hourly-average CO2 measurements from the 396m intake of the WLEF tower near Park Falls, Wisconsin. The name of this example dataset is “co2_lef_tower-insitu_1_allvalid-396magl”. It is distinct from similar records at other intake heights on the same tower, and from flask samples periodically collected from the same intake system.
In addition to records from fixed locations, datasets can also be comprised of measurements from mobile platforms. These should in all cases be distinguished by species, laboratory, sampling methods, and measurement system. Examples include measurements from repeated aircraft profiles with samples at varying heights above a fixed site, measurements collected from ships underway in the ocean, and campaigns such as HIPPO (e.g. “co2_hip_aircraft-insitu_59_allvalid”) and ACT-America (e.g. “co2_act_aircraft-insitu_428_allvalid-c130”).
File format
ObsPack products are composed of data files in netCDF-4 format, with the option to also provide text files. Limitations of the text file format include loss of precision for numerical data and potential complexities with machine reading. In both formats, we define a header with metadata about the file content followed by the body of the file in which the actual data are stored.Dataset-specific netCDF files
The primary delivery format for ObsPack data is using a dataset-specific file. Each file contains the time series of measurements from a distinct dataset and all available metadata for the dataset. These are named using the dataset name. Example: “co2_mlo_surface-flask_426_representative.nc”. This format is naturally useful for time series analysis.File names are unique and include the trace gas species identifier, alphanumeric site/project/campaign code, measurement project, laboratory identification number, a data selection tag, and the file type identifier, e.g., "nc" (netCDF4) and "txt" (text). The file name structure is as follows.
<trace gas identifier>_<site code>_<project>_<lab number>_<selection tag>.<filetype extension>
Below are a few examples.
co2_lef_aircraft-pfp_1_allvalid.txt
co2_lef_surface-pfp_1_representative.txt
co2_lef_tower-insitu_1_afternoon-396magl.txt
co2_lef_tower-insitu_1_nighttime-396magl.txt
co2_nat_surface-flask_26_marine.nc
co2_songnex2015_aircraft-insitu_114_allvalid.nc
co2_con_aircraft-flask_20_allvalid.nc
The selection tag included is intended to convey a very general notion of how the data have been selected. This information including relevant literature references is included in the file.
Daily files
Models usually proceed chronologically and need data for a given date, extracted across all available datasets. The extraction and collation of measurements from a collection of dataset files can be a computational burden best handled in advance of the model run. Thus for some types of analysis, a convenient delivery format for ObsPack data is a collection of “daily” files each containing all available measurements for a given 24-hour period.A limitation of the daily file format is that the metadata for a given dataset are not available in the file header. Since it is not practical to supply the metadata for all datasets in the daily files, these metadata are provided in separate files when the end user requests daily files.
Daily files are named using the ObsPack product name followed by the date in YYYYMMDD format. For example, “obspack_co2_1_GLOBALVIEWplus_v7.0_2021-08-18.20021014.nc”. In this example, 2021-08-18 is part of the ObsPack product name (specifying the date it was created), and 2002-10-14 is the date for which data have been extracted.
Naming the ObsPack product
Each ObsPack data product has a unique ObsPack name using the following structure.obspack_<trace gas identifier>_<preparation lab number>_<product name>_<product version number>_<preparation date>
The version numbering scheme is major.minor[.minor] where a major release is indicated by the first number in the sequence and minor revisions are indicated by the second and third (optional) numbers in the sequence. Below are a few examples.
obspack_co2_1_GLOBALVIEWplus_v1.0_2015-07-30: first major release of GLOBALVIEWplus data product
obspack_sf6_1_v2.1.1_2018-08-17: minor revision to second major SF6 product
obspack_co2_1_ATom_v4.0_2020-04-06: fourth release of the ATom CO2 data product
Please note: The latest minor revision of a major release includes all changes included in intermediate minor revisions if they exist.
Unique identifiers
It is fundamental to be able to uniquely identify a particular measurement in an ObsPack product. We rely principally on the obspack_id string for this purpose. It is intended to be unique not only within a given ObsPack, and also across all ObsPack products.| Name | Description | Variable type | Required |
|---|---|---|---|
| obspack_id | Unique identification string that distinguishes the data item from all other data items both within an ObsPack product, and across any ObsPack data product. It includes obspack_name, dataset_name, and obspack_num, with each field delimited by a tilde (~). | 200-character string, padded with space characters at the end | Yes |
| obspack_num | Unique observation index number across all measurements (from all datasets) in the ObsPack distribution. Ranges from 1 to max_obspack_num. | integer | Yes |
| unique_sample_location_num | This variable uniquely identifies a sample location and datetime. The number assigned to each observation in this variable will be the same in all future ObsPack products including ones for other species measured in that sample. Currently this needs to be assigned by NOAA. | integer | sample_id | This variable uniquely identifies a sample location and datetime, by providing a hash of the x, y, z, and t coordinates. This is currently under development, with the goal of allowing any party to implement the hash. |
Metadata
Metadata are presented as global attributes that describe general features of the dataset, and as variable attributes that describe characteristics of the variables. The dataset information is in the global attributes of the netcdf files, the header of text files, and the in metadata folder (where it is organized in text files named after the dataset). Variable-specific information is provided in attributes belonging to the variable itself.See here for the list of metadata attributes.
Variables
Variables are each dimensioned by the number of observations in the netCDF file. Most are vectors, but some are 2-dimensional arrays for which one of the dimensions (the leading dimension) is the number of observations. This is also the record, or unlimited, dimension in the netCDF file.See here for the list of variables.
Time
Times should be specified using CF conventions. In general, this is provided as the difference in seconds, minutes, or days from a specified reference date. For example: “seconds since 1970-01-01 00:00 UTC”. See https://cfconventions.org/ for further details.The reported time for a measurement should be the central, or average, time and not the beginning or ending time of the measurement or average.
Times should be reported in UTC only. Local time conversions should be handled by the site_utc2lst metadata attribute.
Directory Structure
An ObsPack product is contained in a hierarchy of directories. The name of the root directory in this structure is the product name. The directory structure depends on whether data are being provided in dataset-file format or in daily-file format (Figure 1).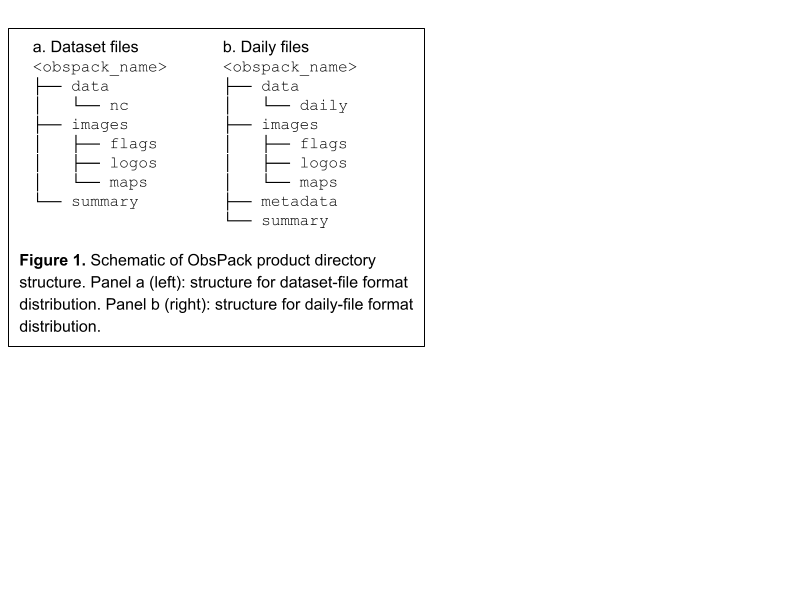
Data directory
The data directory for a product distributed in dataset-file format has a “nc” subdirectory containing the dataset-formatted netCDF files. For a daily-file distribution, the “daily” subdirectory contains the daily files.Images directory
The images directory contains various image files provided for convenience. Strictly speaking, this content is optional. It consists of three subdirectories:- “flags” contains all flags from site_country_flag taken from http://www.flags.net/
- “logos” contains image files of all lab_[#]_logo in png format 100 pixels high
- “maps” contains images of the site location on the globe. An example is shown in figure 2.
Metadata directory
The metadata directory only exists for daily-file format distributions. It contains all of the metadata for the dataset files, provided because the daily files do not contain this information. There is one text file for each dataset, named as <dataset_name>.txt. The content of each file is identical to the netCDF global attributes from the corresponding datafile-format file. Each line of these files is formatted as:<attribute_name> : <attribute_value>
Summary directory
Files in the summary directory provide overall information about the ObsPack product.Citation file
Name: <obspack_name>_citation.txtThis text file contains the required citation for the obspack product.
Dataset summary file
Name: <obspack_name>_dataset_summary.txtThis text file contains a summary of the datasets in the product. It contains the number of contributing laboratories, the number of datasets, the number of observations, and the first and last observation dates. There is also summary information for each dataset:
- dataset_name
- All lab_[#]_abbr and provider_[#]_name and program_[#]_name
- dataset_selection
- dataset_calibration_scale
- dataset_start_date
- dataset_stop_date
Data provider email list file
Name: <obspack_name>_data_provider_email_list.txtThis text file lists all provider_[#]_email in the product in two formats:
- provider_[#]_name (provider_[#]_affiliation_abbr) : provider_[#]_email
- provider_[#]_email,provider_[#]_email
Dataset citations file
Name: <obspack_name>_dataset_citations.txtThis text file contains all required dataset citation information with components:
- dataset_name
- dataset_provider_citation_[#]
- dataset_provider_citation_identifier_[#]